Automatic detection and analysis of techniques for 2D to 3D video conversion
- Author: Polina Pereverzeva
- Supervisor: dr. Dmitriy Vatolin
Introduction
One of the most common methods of 3D movies creation is conversion from 2D. It is a process, where two separate views for each eye are created from one source image.
The most widely used method for 2D to 3D conversion is warping of a source video according to a depth map — Depth Image-Based Rendering (DIBR). Original image pixels are shifted horizontally depending on the corresponding depth value. But at the same time, unfilled areas appear in occlusions — parts of the image invisible in the original frame. Filling such areas is a difficult task that has not been completely resolved yet.
Incorrect filling in occlusions
Valerian and the City of a Thousand Planets

In addition to filling the occlusions, the following conversion methods exist:
- Enlarging the foreground object
Enlarged object example
Spider-Man: Homecoming

- Stretching the background beyond the borders of the foreground objects
Warped background example
Ant-Man

- Removing plot-insignificant objects
Deleted object example
The Legend of Tarzan

This method allows to detect the conversion method and to what extent the final frame differs from the source one.
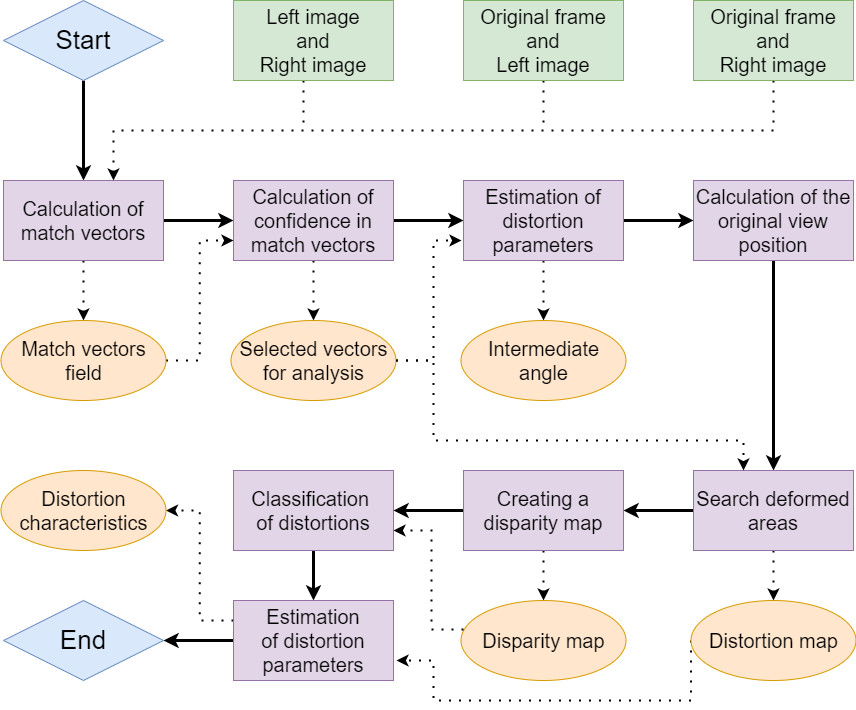
Proposed method
Algorithm scheme
Experiments
To verify the correctness of the classifiers, a test dataset of 35 full-length converted stereoscopic movies containing 4 classes was compiled (1000 examples per class):
- Frames containing only removed objects;
- Frames containing only enlarged objects;
- Frames containing only a deformed background;
- Frames where none of the considered conversion techniques are present.
Analysis of the deformed areas boundaries
Alice Through the Looking Glass



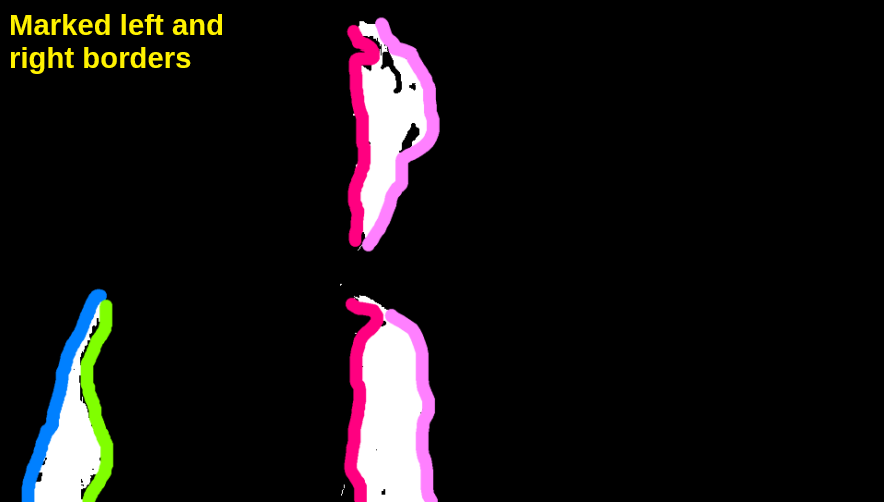
Blue indicates the border with a positive depth change, green and red — the border without any depth changes, purple — the border with a negative depth change.
The evaluation of proposed algorithms on the test dataset are presented on the following graph. The classification accuracy was at least 90%.
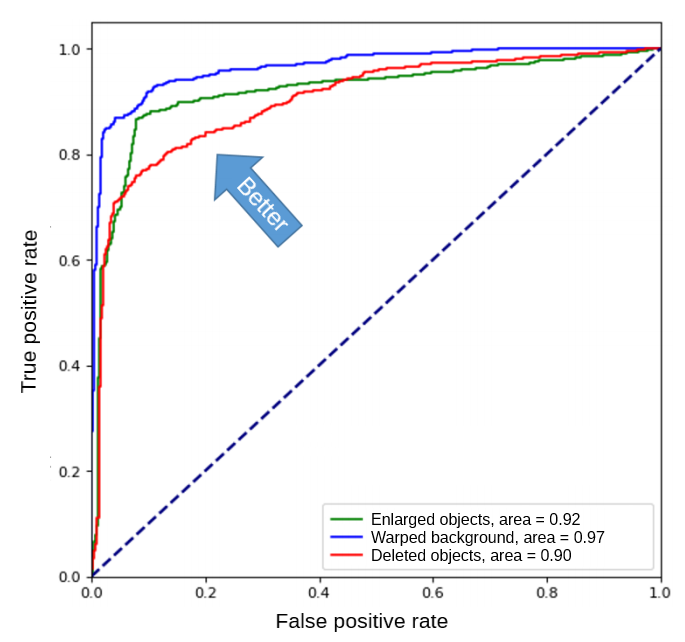
Results
The average runtime of the proposed method for processing video sequences with a resolution of 960 × 540 is approximately 1 second on a computer with the following characteristics: 3.20 GHz Intel Core i5, 8 GB RAM.
-
MSU Benchmark Collection
- Super-Resolution Quality Metrics Benchmark
- Video Colorization Benchmark
- Video Saliency Prediction Benchmark
- LEHA-CVQAD Video Quality Metrics Benchmark
- Learning-Based Image Compression Benchmark
- Super-Resolution for Video Compression Benchmark
- Defenses for Image Quality Metrics Benchmark
- Deinterlacer Benchmark
- Metrics Robustness Benchmark
- Video Upscalers Benchmark
- Video Deblurring Benchmark
- Video Frame Interpolation Benchmark
- HDR Video Reconstruction Benchmark
- No-Reference Video Quality Metrics Benchmark
- Full-Reference Video Quality Metrics Benchmark
- Video Alignment and Retrieval Benchmark
- Mobile Video Codecs Benchmark
- Video Super-Resolution Benchmark
- Shot Boundary Detection Benchmark
- The VideoMatting Project
- Video Completion
- Codecs Comparisons & Optimization
- VQMT
- MSU Datasets Collection
- Metrics Research
- Video Quality Measurement Tool 3D
- Video Filters
- Other Projects