Method for region of interest selection with noticeable stereoscopic distortions in S3D videos
- Author: Denis Kondranin
- Supervisor: dr. Dmitriy Vatolin
Introduction
Shooting 3D with two cameras without proper calibration causes geometric and sharpness distortions. The search of such distortions is manual and time-consuming. So, the special algorithm has been developed. It automates the process of fragments’ selection in stereoscopic frame containing the most noticeable geometric distortions and inconsistency of views in terms of sharpness.
Types of distortions
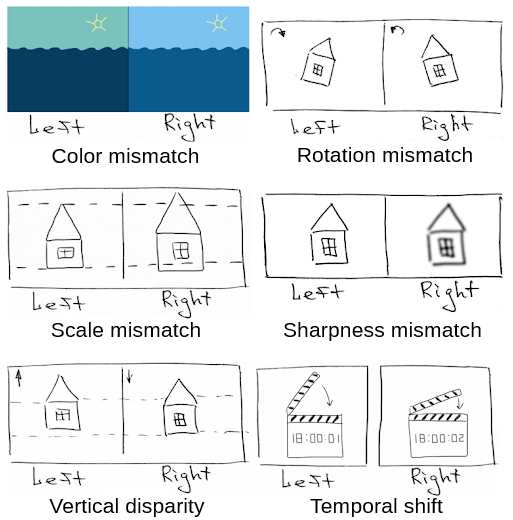
Example of sharpness mismatch

Example of color mismatch
Spy Kids 3D: Game Over

Example of rotation mismatch
Drive Angry


Example of scale mismatch

Example of vertical disparity
Journey to the Center of the Earth 3D
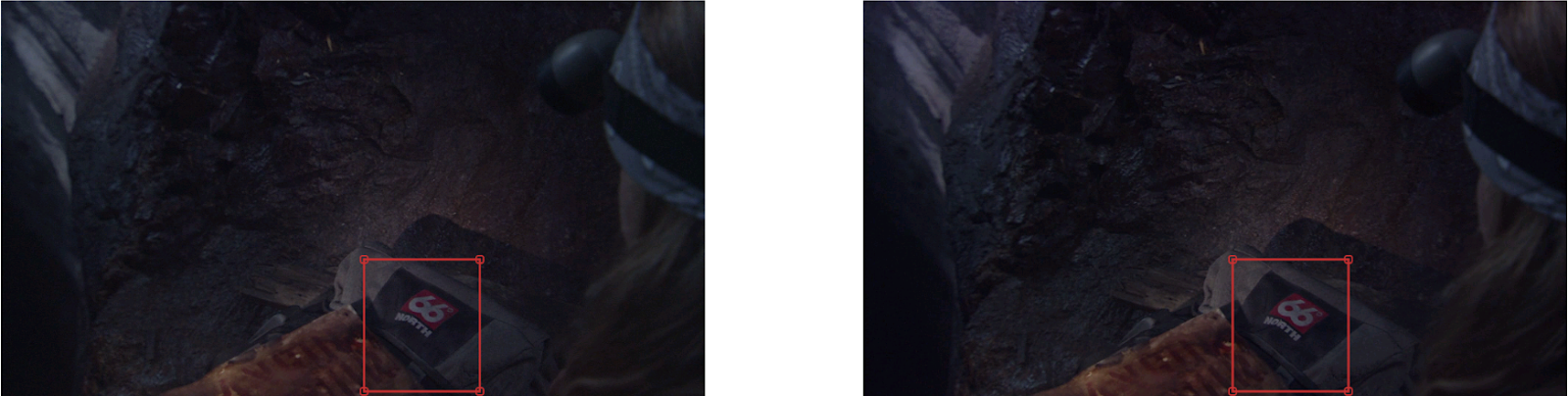

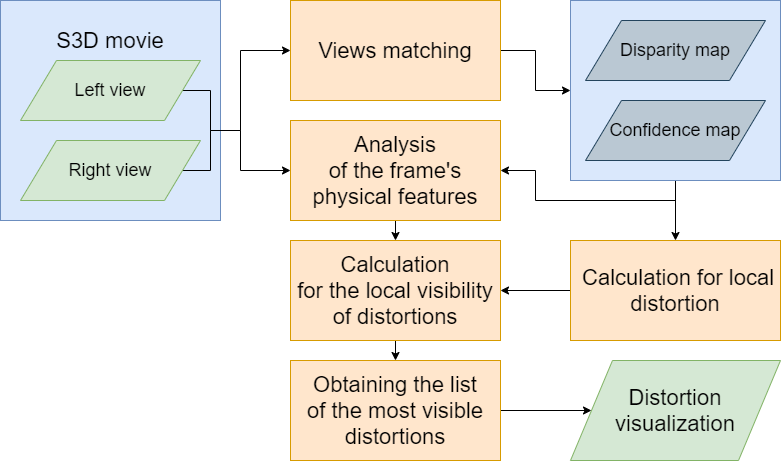
Proposed method
Algorithm scheme
The algorithms of region selection for frames, containing scale, rotation and/or sharpness mismatch, were improved through machine learning methods.
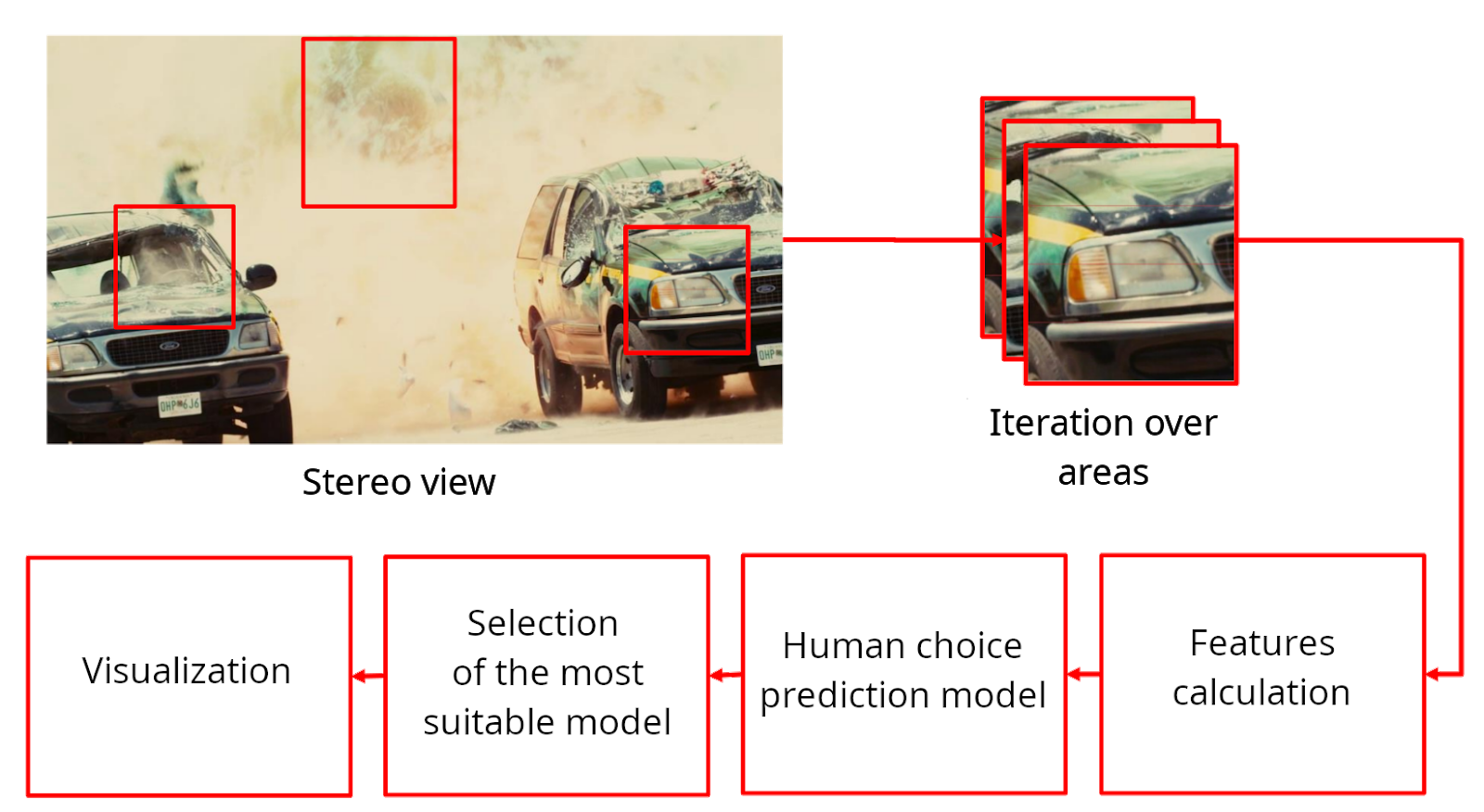
Experiments
A dataset was created to train the model, which would predict the correctness of the detected region. The dataset was made by human experts who selected regions of interest, and consists of:
- 854 annotated bounding-boxes for scale mismatch;
- 1044 annotated bounding-boxes for rotation mismatch;
- 1064 annotated bounding-boxes for sharpness mismatch. The model relies on three types of features:
- The output scalar value of the base algorithm;
- The map of local distortions for both views;
- The saliency map, calculated with SAM-ResNet. Separate models were trained for each type of distortion. Several models were considered:
- Logistic regression;
- Random forest;
- Support vector machine;
- Gradient boosting. There was no leader among the models: different individual base models showed diverse quality of results, depending on the problem. So we decided to apply stacked generalization, and chose logistic regression as a meta-classifier.
The results of classifiers (cross-validation and 95% confidence interval)
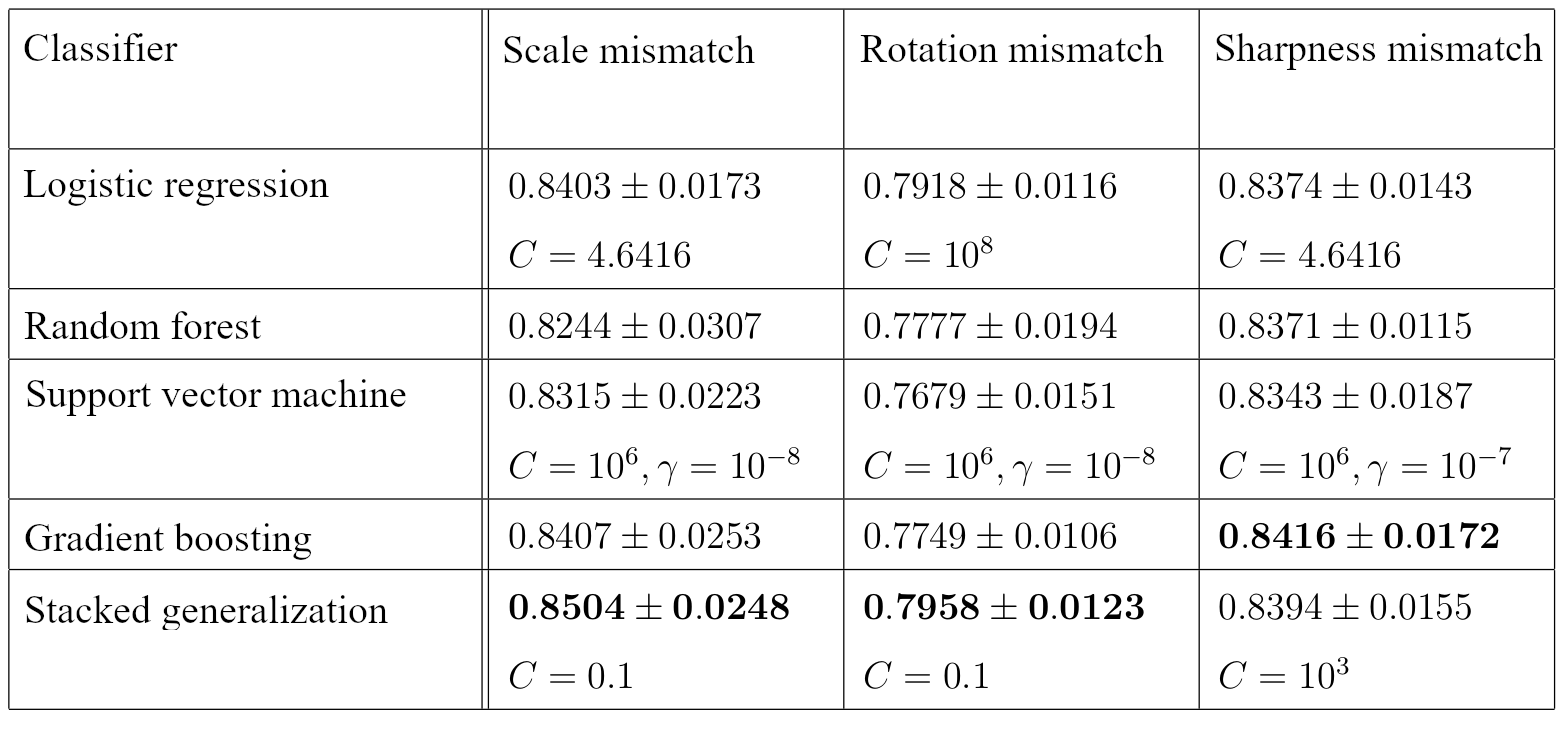 C — regularization weight
𝛄 — kernel parameter
C — regularization weight
𝛄 — kernel parameter
For each type of distortion, we chose the model that showed the best results. The model predicts the region that would likely be selected by an expert.
Results
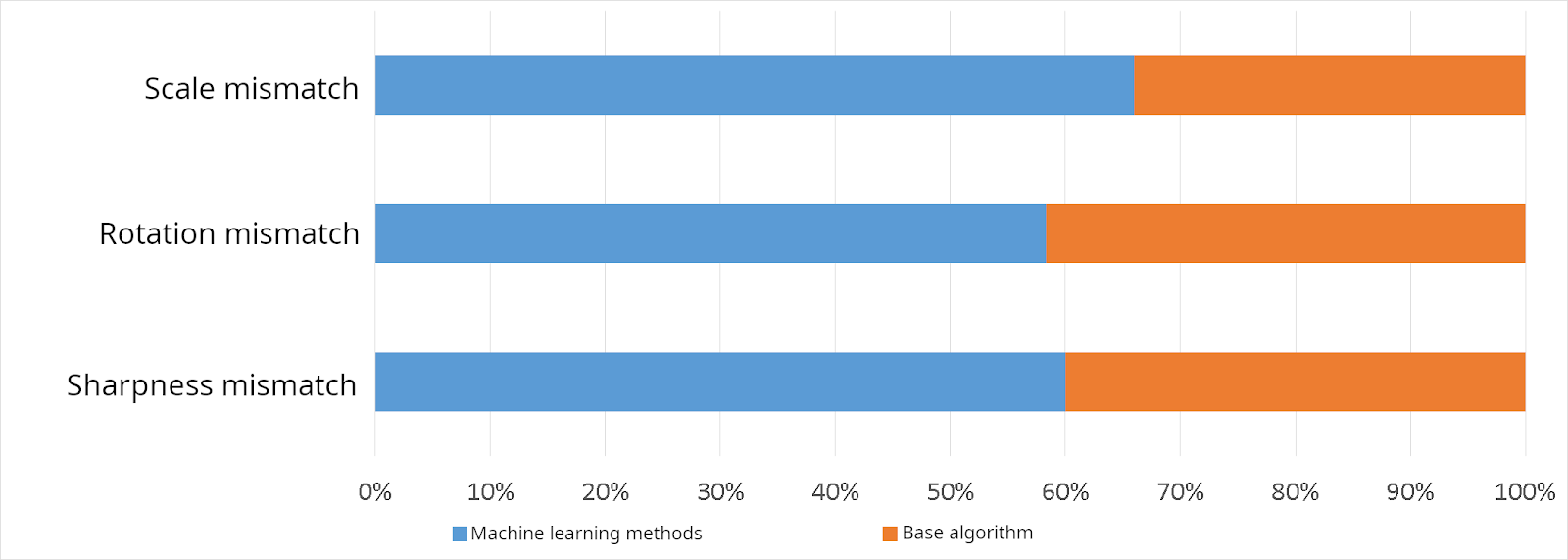
To decide whether the machine learning model is better than the baseline algorithm, we marked 100 additional frames and conducted an expert comparison. Two regions with distortions were shown to each participant: one area from the baseline algorithm and one from the machine learning model. The participants were asked to choose which region was better.
Comparison of the base algorithm and machine learning model
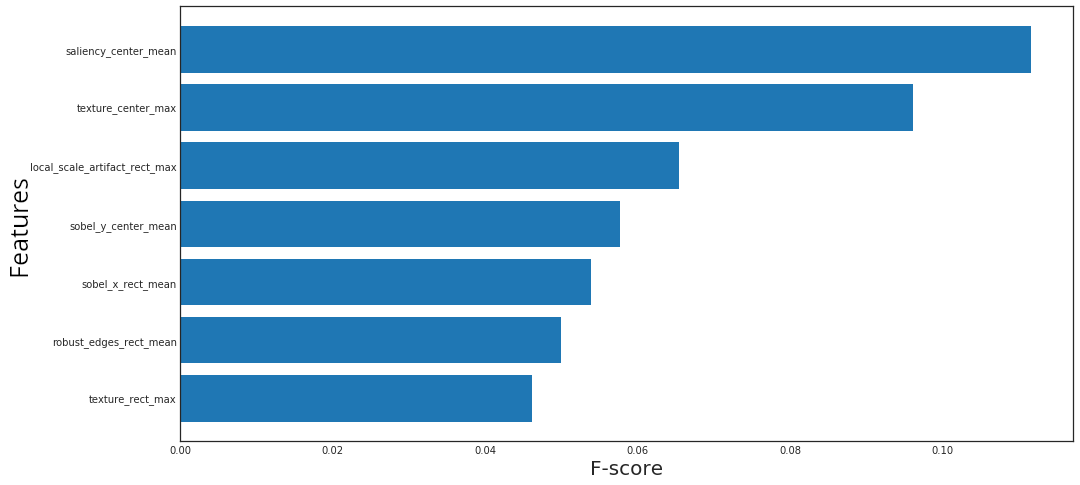
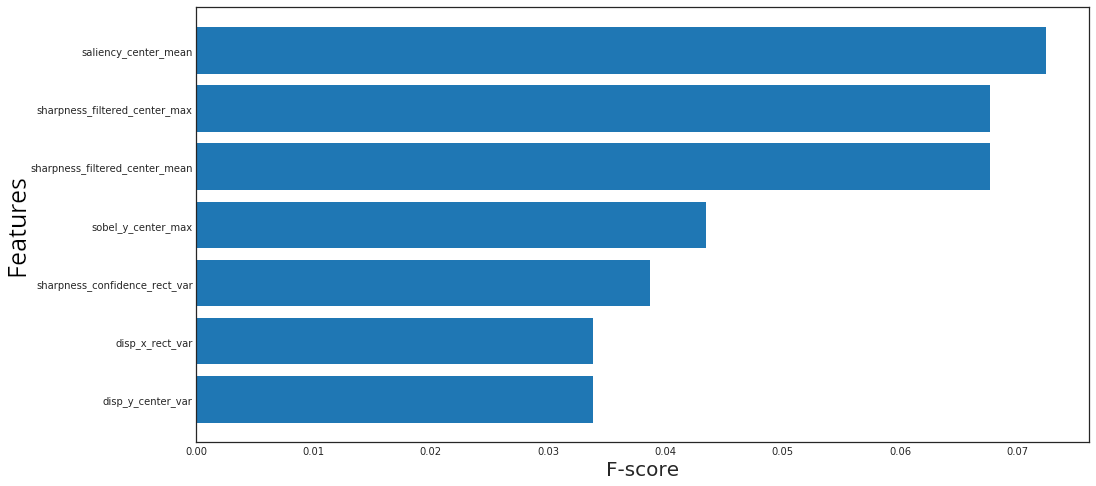
The most important features for scale mismatch
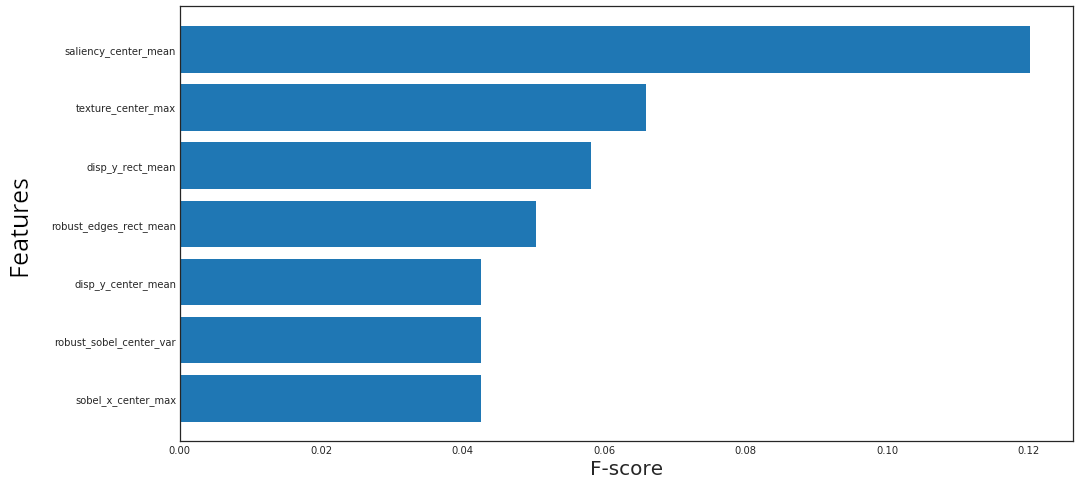
The most important features for rotation mismatch
The most important features for sharpness mismatch
-
MSU Benchmark Collection
- Super-Resolution Quality Metrics Benchmark
- Video Colorization Benchmark
- Video Saliency Prediction Benchmark
- LEHA-CVQAD Video Quality Metrics Benchmark
- Learning-Based Image Compression Benchmark
- Super-Resolution for Video Compression Benchmark
- Defenses for Image Quality Metrics Benchmark
- Deinterlacer Benchmark
- Metrics Robustness Benchmark
- Video Upscalers Benchmark
- Video Deblurring Benchmark
- Video Frame Interpolation Benchmark
- HDR Video Reconstruction Benchmark
- No-Reference Video Quality Metrics Benchmark
- Full-Reference Video Quality Metrics Benchmark
- Video Alignment and Retrieval Benchmark
- Mobile Video Codecs Benchmark
- Video Super-Resolution Benchmark
- Shot Boundary Detection Benchmark
- The VideoMatting Project
- Video Completion
- Codecs Comparisons & Optimization
- VQMT
- MSU Datasets Collection
- Metrics Research
- Video Quality Measurement Tool 3D
- Video Filters
- Other Projects