Evaluation methodology of MSU Video Deblurring
Problem Definition
Deblurring is the process of removing blurring artifacts from images. Video deblurring recovers a sharp sequence from a blurred one. Current SOTA aproaches use deep learning algorithms for this task. Our benchmark ranks these algorithms and determines which is the best by means of restoration quality.
To propose quality comparison we analyze different deblurring datasets. Many of them use gaussian blur to emulate defocus blur. For example, the most popolar datasets on paperswithcode, GoPro and REDS, both incorporate synthetic method of blur creation. RealBlur was the first dataset to suggest using a beam splitter to shoot with real distortion. RealBlur has many scenes with nonprecise matched blurred and ground truth frames because of parallax effect. Nevertheless, they show significant gains achieved by learning from real distortion.
Dataset Proposal
We propose a new real motion blur dataset. Using a beam-splitter rig and two GoPro Hero 9 cameras, we filmed different scenes. We set the stereo base between two cameras to zero and obtain the same scene from two cameras with different shutter speed settings. The camera with higher shutter speed (Camera [2]) captures ground truth frames, while the camera with lower shutter speed (Camera [3]) captures motion blur.
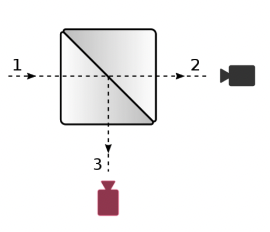
Beam-splitter
We construct a box to protect our cameras and beam splitter from external light. To be able to more precisely manually align cameras and to raise the camera above the beam-splitter glass holder, we construct some stands and screw cameras to them. Then we connect the power and data cables to the cameras. Also, the walls of the box were covered with black matte sheets of paper for better light absorption and to increase the reflective properties of the beam-splitter at the time of shooting. The beam splitter itself was vertically aligned at 90 degrees angle.

Alignment
We disable optical stabilization and manually set all the available settings, such as ISO, focus distance, and color temperature. We film our sequences in 4K 60 FPS, and then crop regions of interest.
To achieve precise ground truth data it is crucial to film scenes without parallax present. The parallax is a difference in apparent position when an object is viewed along the two lines of sight. During post-processing, we can precisely correct affine mismatches between cameras, namely scale, rotation angle, and transition, but we cannot correct parallax without using complex optical flow algorithms that can affect our ground truth data quality.
For coarse alignment, we firstly visually aligned the lenses to obtain a visual zero stereo base. Then we point two cameras at one scene, using a photo from one camera and a video stream from another. After making sure that the parallax is not present we film all scenes in one go.
Scene selection
We use simple scenes to focus on a complex analysis of motion blur. We placed objects on a table with a white background 1.5 meters from the camera. We have aquired 23 sequences with different types of motion and objects using two GoPro Hero 9 cameras.
Post-processing
For post-processing, we use a simple pipeline to minimize ground truth data tampering. Given the two videos from cameras, we first horizontally flip the blurred view, then we match the blurred view to the ground truth view using a homography transformation. For the estimation of transformation parameters, we utilize SIFT features, FLANN matcher, and the RANSAC algorithm. To correct beam splitter color distortions we use [1] VQMT3D color correction algorithm.
Dataset preview
In this section you can observe the frames from the public videos included in the dataset










Dataset comparison
| Dataset | Image/Video | Blur type | Motion | Matching colors on GT and target frames |
Parallax present |
|---|---|---|---|---|---|
| GoPro | Image | Synthetic | Camera movement | True | No |
| REDS | Image | Synthetic | Camera movement | True | No |
| HIDE | Image | Synthetic | Camera movement | True | No |
| RealBlur | Image | Real | Camera movement | False | Yes |
| Ours | Video | Real | Different objects moving in scene | True | Minimal |
Metrics
PSNR
PSNR is a commonly used metric for reconstruction quality for images and video. In our benchmark, we calculate PSNR on the Y component in YUV colorspace.
For metric calculation, we use MSU VQMT[2].
SSIM
SSIM is a metric based on structural similarity.
For metric calculation, we use MSU VQMT[2].
VMAF
VMAF is a perceptual video quality assessment algorithm developed by Netflix. In our benchmark, we calculate VMAF on the Y component in YUV colorspace.
For metric calculation, we use MSU VQMT[2].
For VMAF we use -set "disable_clip=True" option of MSU VQMT.
LPIPS
LPIPS (Learned Perceptual Image Patch Similarity) evaluates the distance between image patches. Higher means further/more different. Lower means more similar.
To calculate LPIPS we use Perceptual Similarity Metric implementation[3] proposed in The Unreasonable Effectiveness of Deep Features as a Perceptual Metric[4].
ERQA
ERQAv2.0 (Edge Restoration Quality Assessment, version 2.0) estimates how well a model has restored edges of the high-resolution frame. This metric was developed for MSU Video Super-Resolution Benchmark 2021[5].
Firstly, we find edges in both output and GT frames. To do it we use OpenCV implementation[6] of the Canny algorithm[7]. A threshold for the initial finding of strong edges is set to 200 and a threshold for edge linking is set to 100. Then we compare these edges by using an F1-score. To compensate for the one-pixel shift, edges that are no more than one pixel away from the GT's are considered true-positive.
More information about this metric can be found at the Evaluation Methodology of MSU Video Super-Resolution Benchmark[8].

Figure 2. ERQAv2.0 visualization.
White pixels are True Positive, red pixels are False Positive, blue pixels are False Negative
References
- https://videoprocessing.ai/stereo_quality/local-color-correction-s3d.html
- http://compression.ru/video/quality_measure/video_measurement_tool.html
- https://github.com/richzhang/PerceptualSimilarity
- R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, "The unreasonable effectiveness of deep features as a perceptual metric," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2020, pp.586-595.
- https://videoprocessing.ai/benchmarks/video-super-resolution.html
- https://docs.opencv.org/3.4/dd/d1a/group__imgproc__feature.html#ga04723e007ed888ddf11d9ba04e2232de
- https://en.wikipedia.org/wiki/Canny_edge_detector
- https://videoprocessing.ai/benchmarks/video-super-resolution-methodology.html
-
MSU Benchmark Collection
- Super-Resolution Quality Metrics Benchmark
- Video Colorization Benchmark
- Video Saliency Prediction Benchmark
- LEHA-CVQAD Video Quality Metrics Benchmark
- Learning-Based Image Compression Benchmark
- Super-Resolution for Video Compression Benchmark
- Defenses for Image Quality Metrics Benchmark
- Deinterlacer Benchmark
- Metrics Robustness Benchmark
- Video Upscalers Benchmark
- Video Deblurring Benchmark
- Video Frame Interpolation Benchmark
- HDR Video Reconstruction Benchmark
- No-Reference Video Quality Metrics Benchmark
- Full-Reference Video Quality Metrics Benchmark
- Video Alignment and Retrieval Benchmark
- Mobile Video Codecs Benchmark
- Video Super-Resolution Benchmark
- Shot Boundary Detection Benchmark
- The VideoMatting Project
- Video Completion
- Codecs Comparisons & Optimization
- VQMT
- MSU Datasets Collection
- Metrics Research
- Video Quality Measurement Tool 3D
- Video Filters
- Other Projects